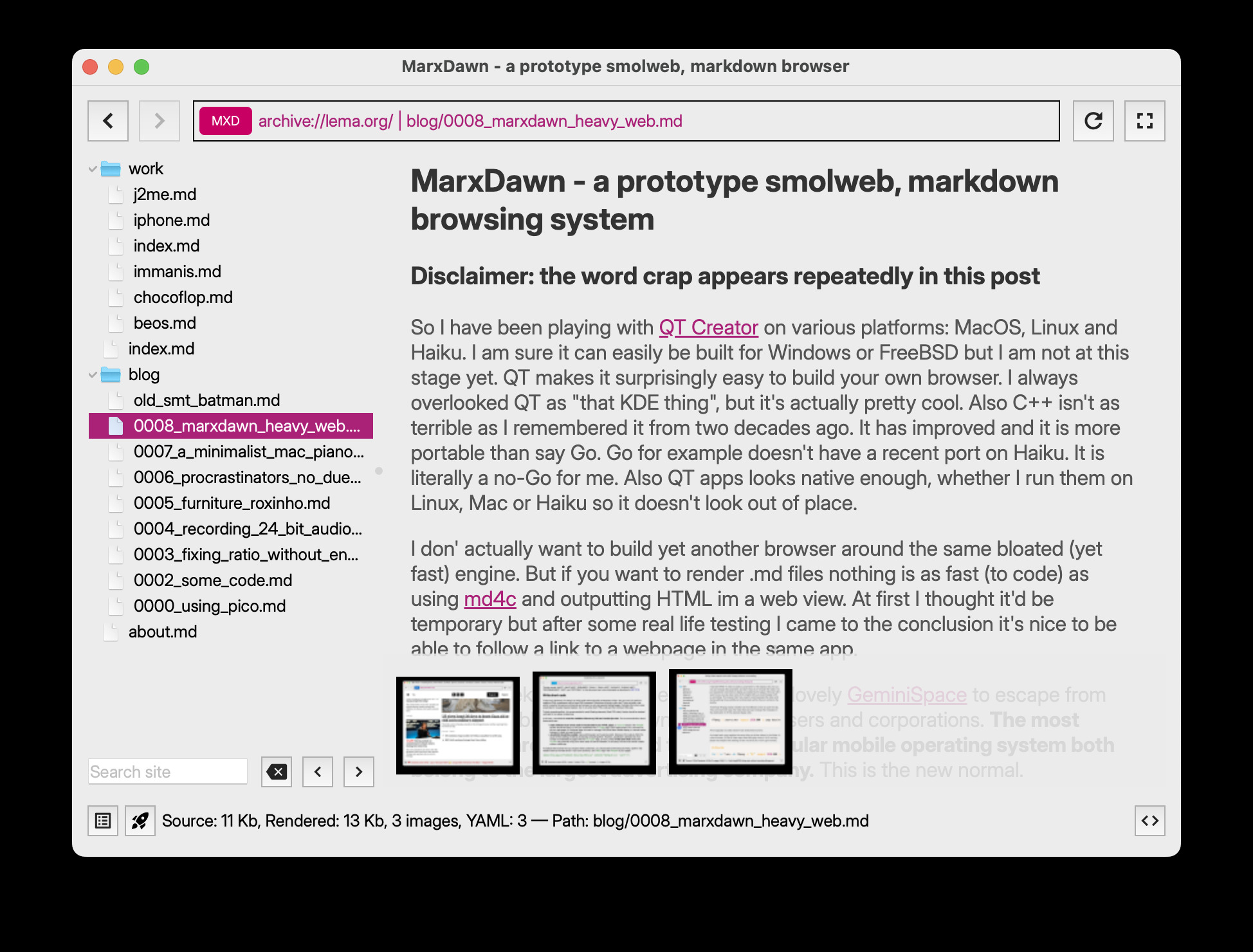
MarxDawn - a smolweb, markdown browsing system
Disclaimer: the word crap appears repeatedly in this post. A natural consequence of looking at the web in 2024.
So I have been playing with QT Creator on various platforms: MacOS, Linux and Haiku. I am sure it can easily be built for Windows or FreeBSD but I am not at this stage yet. QT makes it surprisingly easy to build your own browser. I always overlooked QT as "that KDE thing", but it's actually pretty cool. Also C++ isn't as terrible as I remembered it from two decades ago. It has improved and it is more portable than say Go. Go for example doesn't have a recent port on Haiku. It is literally a no-Go for me. Also QT apps look native enough, whether I run them on Linux, Mac or Haiku so it doesn't look out of place.
This is what it looks like so far: essentially you get the full text of all the site in a zip file and you browse contents in a tree view. Markdown is converted for viewing directly on the client. At this point you could pull the cable and read offline.
Check this post to see it running on Haiku on a laptop from two-decades ago (older build)
I don't actually want to build yet another browser around the same bloated (yet fast) engine. But if you want to render .md files nothing is as fast (to code) as using md4c and outputting HTML im a web view. At first I thought it'd be temporary but after some real life testing I came to the conclusion it's nice to be able to follow a link to a webpage in the same app.
Humans seek radical changes such as the lovely GeminiSpace to escape from the modern bloated web owned by advertisers and corporations. The most popular search engine and the most popular mobile operating system both belong to the largest advertising company. This is the new normal.
I love GeminiSpace but it requires to enter a fully separate world. That's the beauty of it. However I think progressive change has more chances to attract people who are not emacs or vim users so to speak.
So I am writing a multi-platform C++ GUI app with QT. Instead of doing my actual work... My goal is for the app to be confortable to use on a Core 2 Duo. Not a random choice, this happens to be the processor in my 2006 ThinkPad T60. Of course I code on my M1 Mac since I am not a masochist: friends don't let friends use clangd on an 18 year old machine.
I test on Haiku on the old Thinkpad regularly. Nothing like real conditions to make sure it doesn't get too bloated. Haiku does not even have GPU acceleration so you think twice before instantiating 173 web views. With only one webview and (nearly) no javascript it is suprisingly responsive on an old machine. I doesn't start as instantly as NetSurf because it has to launch the whole QtWebEngine which is based on Chromium — An operating system of its own — but rendering of CSS and webpages is perfect.
Later iterations obviously could drop the heavy webview or even the desktop GUI altogether in favor of a TUI or a mobile app. That's the good side of having the source markdown, you, the reader, decide how you want to display it. See it on your iPhone or pass it through a serial proxy to read it on your Commodore 64, it's all the client's choice.
Why MarxDawn (and all the others smolweb projects) ? The modern web just can't be saved
If you are old enough you remember a time when salesmen would ask if you wanted to use PhotoShop or just MS Word. Nowadays the question is probably "Do you want your computer to be able to open the BBC website or just some casual 4K Raytracing?"
The MarxDawn prototype can browse the "normal" HTML/CSS/JS web also. And so doing it can also point out its aberrations. When you aim it at the BBC website you will notice the absurd disproportion between the actual text content (a few kilobytes at most) and all the bloat around it. I am not a religious person but I think many will understand the level of madness of the modern web when markup and scripts are sometimes heavier than the Bible itself. That's about 5 million characters. About 0.1% is actual content and the rest is shiny 💩 around it.
Check this BBC screenshot in MarxDawn prototype browser: As you can see on the red status line at the bottom, we get 82% of the size of the Bible just in the 39 — YES THIRTY-NINE - scripts and associated markup. It's almost as absurd as threatening to retire military aid because the country that uses your free weapons to kill people isn't sending enough help... to the very same people they are bombing. With your free bombs. But I digress.
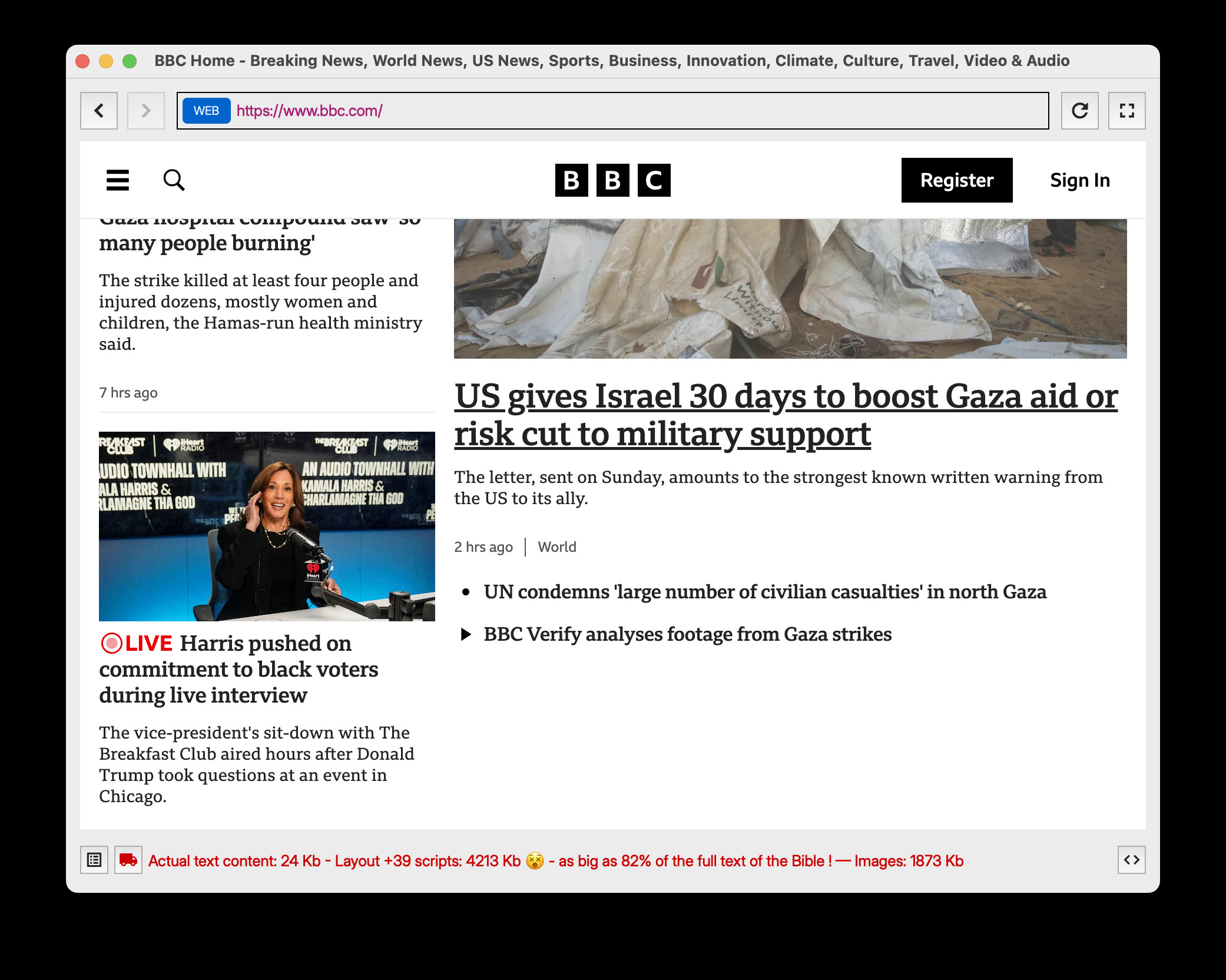
Each time you click on an article you effectively download the equivalent of a complete Bible . And it's not once per website. Because you see, to avoid being filtered out those lovely javascript files are often obfuscated and included in the body of each page with more random data. For some reason, people want to remove the merdouille(*) around the article they'd like to read.
(*) I mean crap, but I wrote crap too many times on this page already.
We could say we don't care as our phones are powerful enough to handle it (mostly). But if it actually downloaded a large book with every page I wouldn't mind. You read an article about football and boom you get a free backup copy of Das Kapital. One can dream.
The problem is we don't get free books. We get a good 5 megabytes of BS to track you on behalf of advertisers. These people are planning to sell plastic toys on a good day or help overthrow a business-unfriendly democratic government on a rainy Monday. Ah, 2013-2022 Brazil: good times for politically oriented advertising.
The smolweb movement
As you can see in this screenshot some websites are nearly as small in HTML as a markdown file. The MarxDawn browser acknowleges it with a small plant emoji 🌱. A reference to Wall-E. I guess. Remember the little plant that survived on the immense pile of crap. This is it.
Behold a site that has actually more content than markup / scripts. Something you probably haven't seen in a while on the web. So there is salvation. Some people ARE doing it. It just needs to be normalized, promoted and given value.
A MXD archive is just a zip with your source markdown files
The MarxDawn browser can browse simple .md files via http(s), as if these were webpages. It just gets them, pass them through md4c, adds in some minimal CSS and display the very small resulting webpage. As a content creator you have to setup your webserver to serve your .md files along with your existing HTML blog and there you are. I am still thinking about the implementation details but I want the thing to be easy to do on top of existing content.
This blog here uses PicoCMS but Hugo and others are all very similar: they take a bunch of markdown files in a folder and render them to HTML. What MarxDawn intends to do is move this rendering to the client and in the same way give the user 100% control over the appearance of what he reads.
One thing I noticed is that most sites don't have more text that can fit on a 1.44MB floppy disk. And text, is — I believe — the thing we actually want to read. TikTok users may disagree.
For example Bertrand's Blog is around 900kb of text for ~20 years of moderate blogging. Thankfully his site is available on github so I was been using it along with a few others to experiment. My blog here has been really anemic since I re-started it a few years ago. This here is the first post in 3 years. So I am glad I can test with longer content. Who know I may start posting more now that I can blog about huh, blogging.
I came to this conclusion : if we agree to download 5 megabytes of privacy-invading & CPU-burning shit to see the home page of CNN with little actual content, why can't we get 1 MB of uncompressed text each time some author we care about writes a long blog post ? Because if we did we could just grab a zip file with all the markdown that person has ever written and read our local copy.
MXD has some pratical advantages:
-
it takes a second or two to get the archive, not different from most web pages. If you have the cheapest fiber connection DNS resolution can take as much time as downloading
-
navigation afterwards is instantaneous as it happens all in RAM
-
you can search the whole site locally. See it's about 1 Megabyte of RAM used to have the whole site in markdown. It's fast for everything.
-
It works offline. One click before you hop on a plane and you can read 10 blogs offline with thousands of pages. In a way much better than Instapaper.
-
It is easy to implement on the server. A short bash script can build the zip and a corresponding md5. You keep your blog system. Ideally the client app will be adapted to the most popular ones.
-
Server costs can be reduced to a minimum. You don't need processing power for search as the client does it. One can even imagine self hosting on a machine that isn't online 24/h.
MXD archives are great for privacy
You know the best way to preserve privacy with security cameras: you don't turn them on. One cannot steal videos that don't exist. And it is so for your privacy on the web. Less movement = less stuff to be intercepted.
Privacy is better preserved when you get a whole site archive than when you browse. As the only information one could intercept is IP:x.x.x.x got site:ThatBlog.dev. What you searched for, for how long, what you clicked well all of that happens in RAM on your machine. The server, just knows nothing except it served one ZIP file (and subsequent updates).
If you use a VPN for privacy, all you need is one request and you can go offline. Sure you can get images etc but the client will decide whether or not it asks for them.
Nobody will enable MXD archives for their site ?
Hey but not everyone wants to give you all their life content as a zip file ! Turns out a lot of interesting people do. The content is often even on github. If they shared it with Microsoft, they can share it with you and me. Those who want to nickel and dime you for each piece of advice on Medium are usually less interesting. It's ok if we don't get everything. The other web still exists.
Another issue that will arise is that this requires work. Well technically it's a cron line to re-create a zip file every day (if you don't want to bother detecting changes). That's not zero work but compared to setting up a gemini server it's an easier transition that dropping the http protocol altogether. After all you only need to run a zip command after a post is updated and the client should deal with the rest.
I believe once the client is ready and works nicely with a few example sites, others may follow with integration and of course write other clients based on the same principle.
Why MarxDawn for a Markdown browsing system, do you like confusion ?
Yes. I love chaos and confusion. As stated on the official marxdawn.org website the name was chosen because I want to make sure a corporation will not approach this project. We had free, they stole the meaning of free. We had open they stole the meaning of open. So I went with MarxDawn because it rolls of the tongue in a more elegant manner than FuckThisWholeShitCapitalistSystem®, the browser.
It will be ready when it is done (and open-source)
I have no real plans. I am just trying out stuff in the hope in the end it will make sense and be maybe useful for someone. It's just easier for me to just sit down, write code and get a prototype than write a long doc before knowing if any of this makes sense.
At the point of this writing I haven't released the source but I will as soon as it's a bit cleaner as the app is released. It will be GPL (kind of the only free option when using QT).
Bonus: This article in MarxDawn
So after writing this I of course updated the zip file and checked it out in the MarxDawn browser. I couldn't resist adding a screenshot of this article, to this article. I hope I am not messing with the space-time continuum.
As you can see this article was 11kb (without this addendum!) and this is all the browser downloaded aside from the images.